")
对于从事Java开发的小伙伴而言,“线程池”一词应当不陌生,虽然在实际工作、项目实战中可能很少用过,但是在工作闲暇或吹水之余还是会听到他人在讨论,更有甚者,在跳槽面试等场合更是屡见不鲜,已然成为一道“必面题”。
从本文开始我们将开启“Java线程池实战总结”系列文章的分享,帮助各位小伙伴认识、巩固并实战线程池的相关技术要点。
1、吹一波“线程池”
“线程池”,字如其名,是“线程”+“池”合并得来的,“线程”的含义自然不用多说,而“池”其实是一种“设计思想”,即池化设计技术,这种思想简而言之是为了能更好地重复利用资源,减少因资源重复创建而带来的损耗,提高资源重复利用率。
“池化设计”带来的产物有很多,目前在市面上我们经常可以见到的有“数据库连接池”、“Http连接池”、“Redis连接池”以及我们本文要介绍的“线程池”等等,都是对这种设计思想的应用。
线程池提供了一种限制和管理“线程”资源的机制,池里面的每个线程所承担的职责无非就是执行项目、程序中待执行的任务,当待执行的任务数量大于1时,线程池中预先分配好的多个线程便起到了作用,当执行完任务后,线程并不会立即被Kill掉,而是会保留在线程池一段时间,等待下次被重复利用。
2、面试必考 ~ “线程池”的好处
在这里借用《Java 并发编程的艺术》一书里提到的关于使用线程池的好处(这是重点,要圈起来,必考的):
A.降低资源消耗 ~ 通过重复利用已创建的线程降低线程创建和销毁造成的消耗;
B:提高响应速度 ~ 当任务到达时,任务可以不需要等到线程创建就能立即执行;
C:提高线程的可管理性 ~ 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,而使用线程池则可以进行统一的分配,调优和监控
3、基于ThreadPoolExecutor实现百万数据的批量插入
接下来,我们以实际项目中典型的业务场景“多线程批量插入随机生成的200w条数据”为案例,初步认识并了解Java中如何使用线程池 ThreadPoolExecutor 做一些事情。
(1)首先,我们得先定义这些事情,也就是“任务” 是什么,特别是要让我们的系统、线程知道待执行的每个“任务”是什么,很显然,我们的任务是“插入数据”,而这些数据将插入数据库表 book中,该数据库表的DDL定义如下所示:
CREATE TABLE `book` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '书名', `author` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '作者', `release_date` date DEFAULT NULL COMMENT '发布日期', `is_active` tinyint(255) DEFAULT '1' COMMENT '是否有效', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='书籍信息表'
而这个任务其实可以通过 实现 Runnable 接口或者 Callable 接口来定义,只有通过这种方式定义,我们的系统才认识,如下代码所示:
class insertTask implements Callable<Boolean>{ @Override public Boolean call() throws Exception { Book b; String msg; for (int i=0;i<50000;i++){ b=new Book(); msg=snowflake.nextIdStr(); b.setName(msg); b.setAuthor(msg+"-A"); b.setReleaseDate(new Date()); bookMapper.insertSelective(b); } return true; } }
在上述代码中,我们定义了每个线程待执行的“任务”:循环插入 5w 条数据,其中,为了避免多线程并发生成相同的数据,我们采用了雪花算法工具生成了“全局唯一ID”;而200w的数据,需要在外部循环遍历 40次,如果用传统的“单一线程”进行实现,很显然是行不通的(那得插到天昏地暗才能完成….)
(2)有了任务,那么接下来就需要有“线程”去执行,在这里我们需要定义线程执行器 ThreadPoolExecutor 实例,即用于在线程池创建 N 个线程,并用于执行这 40个 任务,其源码如下所示:
@Autowired private BookMapper bookMapper; private ArrayBlockingQueue queue=new ArrayBlockingQueue(8,true); private ThreadPoolExecutor.CallerRunsPolicy policy=new ThreadPoolExecutor.CallerRunsPolicy(); private ThreadPoolExecutor executor=new ThreadPoolExecutor(4,8,10, TimeUnit.SECONDS ,queue,policy); private static final Snowflake snowflake=new Snowflake(3,2); @Test public void testBatchInsert() throws Exception{ List<insertTask> tasks= Lists.newLinkedList(); for (int j=0;j<40;j++){ tasks.add(new insertTask()); } executor.invokeAll(tasks); }
点击运行该单元测试方法,之后需要等待一定的时间,最终你会在IDEA控制台看到同时会有好几个线程并行插入数据,在数据库表中也最终可以看到其成功插入了 200w 条数据,如下图所示:
 ...
...
4、说道说道ThreadPoolExecutor
(1)对于 ThreadPoolExecutor,可以说在实际项目中算是很常见的了,其顶层实现类为Executor,继承关系如下所示(通过看源码就可以一眼得到):
 ...
...
(2)主线程首先需要创建实现 Runnable 或者 Callable 接口的任务对象,并把创建完成的 Runnable/Callable接口的对象实例直接交给 ExecutorService 执行,即主要通过 execute()或者submit()执行或者invokeAll()。
(3)接下来分析一下创建 ThreadPoolExecutor 的源码,ThreadPoolExecutor 类中提供了4个构造方法,我们只需要看最长的那个,因为其余三个都是在这个构造方法的基础上产生的,如图所示:
 ...
...
(4)下面重点介绍一下其中的几个参数:
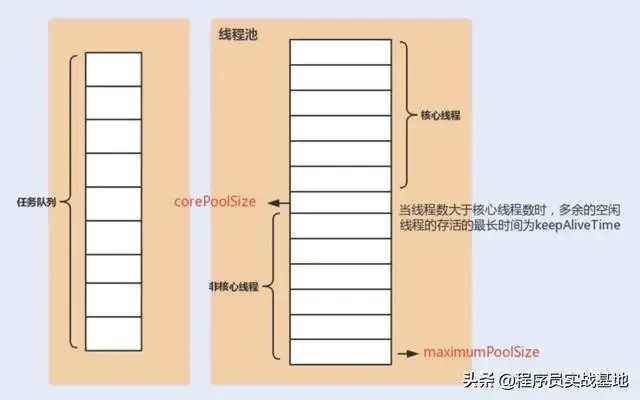
A. corePoolSize:核心线程数定义了最小可以同时运行的线程数量
B. maximumPoolSize:当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量将变为最大线程数
C. workQueue:当新任务到来是,系统会先判断当前运行的线程数是否已达到核心线程数,如果达到的话,新任务就会被存放在队列中
D. keepAliveTime:当线程池中的线程数量大于 corePoolSize 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 keepAliveTime才会被回收销毁
E. unit:keepAliveTime 参数的时间单位
F. threadFactory:executor 创建新线程的时候会用到
G. handler:饱和策略,下面会单独介绍
下面这张图或许可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java
性能调优实战》)
 ...
...
(5)ThreadPoolExecutor 饱和策略定义:如果当前同时正在运行的线程数量达到了最大线程数量并且队列也已经被放满了任务时,ThreadPoolTaskExecutor 将定义一些策略:
A.ThreadPoolExecutor.AbortPolicy:抛出 RejectedExecutionException来拒绝新任务的处理。
B.ThreadPoolExecutor.CallerRunsPolicy:调用执行自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
C.ThreadPoolExecutor.DiscardPolicy:不处理新任务,直接丢弃掉。
D.ThreadPoolExecutor.DiscardOldestPolicy:此策略将丢弃最早的未处理的任务请求。
附带一提:当我们不指定 RejectedExecutionHandler 饱和策略的话来配置线程池的时候默认使用的是 ThreadPoolExecutor.AbortPolicy
5、实际项目中的使用建议
(1)在《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 构造函数的方式,这样的处理方式是为了让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
(2)Executors 返回线程池对象的弊端如下:
A.FixedThreadPool和SingleThreadExecutor:当允许请求的队列长度设置为 Integer.MAX_VALUE 时,很有可能系统会堆积大量的请求,从而导致 OOM;
B.CachedThreadPool和ScheduledThreadPool:当允许创建的线程数量设置为 Integer.MAX_VALUE时,则很有可能会创建大量线程,从而导致 OOM
6、总结
本文我们先初步认识一下Java中经常使用的线程池ThreadPoolExecutor,下一小节我们将接着本节的内容,分析分析 ThreadPoolExecutor 的执行与设计原理。
我是Debug,关注我一起学习一起成长吧~
